The GigaScreen method combines machine learning and deep learning tools to tackle the computational intensity of screening very large chemical databases. To overcome these challenges several protocols are employed:
One of the advantages of the GigaScreen protocol is that large giga-sized libraries can be screened on a single box, eliminating the need for expensive computational resources or additional software.
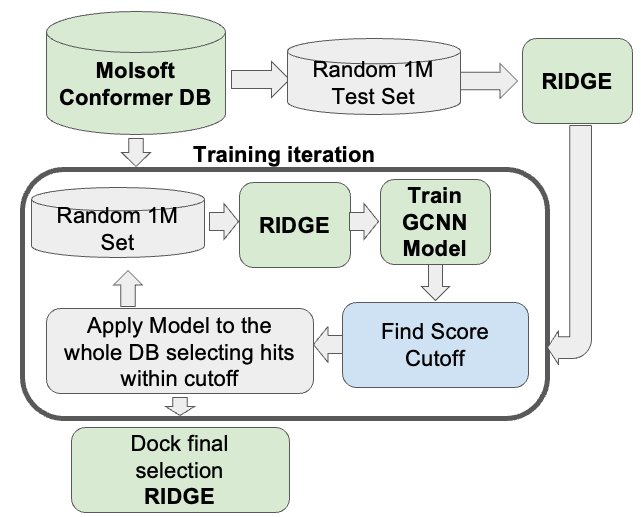
The core concept involves selecting small subsets or batches of the initial database and iteratively building and improving a 2D model utilizing fingerprint ECFP and Chemical Graph Convolutional (GCNN) models.
For the random size selection, it is recommended to choose a subset comprising 0.1% of the database size, which translates to one to two million entries. To begin the process, two random sets are initially selected-one for testing and the other for the first iteration of the training process.
During each iteration, the selected set is trained using the GCNN model. The trained model is then applied to the entire database, and the top hits are identified using a score cutoff. The suggested cutoff value is such that the model's top hits contain 80% of the top 0.1 hits by RTCN and Squad scores. The exact value of the cutoff (ranging from 75% to 90%) can be adjusted based on the specific needs. If the resulting number of compounds is still large, another random million is selected, and the process is repeated multiple times with the expectation that the model will improve.
To monitor the improvement of the model, two parameters can be observed. The first parameter is the 25th percentile score from each iteration after docking, with the aim of improving the RTCNN score throughout the training process. The second parameter is the number of compounds remaining after applying the score cutoff. Ideally, this number should decrease with each iteration to a manageable level, such as reducing it by randomly selecting a percentage of the remaining compounds.
One of the advantages of the GigaScreen protocol is that it can be executed on a single box, eliminating the need for expensive computational resources or additional software. The provided GigaScreen script enables running the entire process on this setup. On a RTX 4090 GPU and an AMD processor, a database size of two billion, each training iteration takes approximately 15 hours using this hardware configuration. Considering the five iterations, docking the test set, and back-end processing, the complete process can be completed in about three to four days.
The implementation is provided as a single script with adjustable parameters.
© 2026 All Rights Reserved MolSoft LLC Terms of Use | Privacy Policy



